I am a Research Scientist at VCV-Science group at Apple where I work on vision foundation models. Prior to that, I was a CS Ph.D. student and graduate researcher at Oregon State University supervised by Prof. Fuxin Li.
My research interests mainly include foundation models, generative models, 2D/3D computer vision, interpretability, long-tail problem, self-supervised learning.
My research interests mainly include foundation models, generative models, 2D/3D computer vision, interpretability, long-tail problem, self-supervised learning.
News [outdated]
- Mar 22: Our counterfactual visual explanation paper "Cycle-Consistent Counterfactuals by Latent Transformations" (C3LT), is accepted to the CPVR 2022! (acceptance rate 25.33%) [PDF] [Github]
- Oct 21: Our paper "From Heatmaps to Structural Explanations of Image Classifiers" is accpeted to the Applied AI Journals! [PDF]
- May 21: Our paper "Re-Understanding Finite-State Representations of Recurrent Policy Networks" is accpeted to the ICML 21! (acceptance rate 21.4%) [PDF]
- May 21: Our new paper on flexible training of deep networks using ADMM titled "Stochastic Block-ADMM for Training Deep Networks " is now available on arXiv. [PDF]
- Feb 21: Code for iGOS++ is released! This repo also includes faster version of I-GOS! [Github]
- Feb 21: Our paper "iGOS++: integrated gradient optimized saliency by bilateral perturbations" is accepted to the ACM-CHIL 21! iGOS++ shows significant imporvement over I-GOS, particularly in terms of insertion score! (acceptnace rate ~27%) [PDF]
- Jan 21: I joined Scale AI as a Machine Learning Research Engineer Intern starting January 2021.
- Nov 20: Our paper "Embedding Deep Networks into Visual Explanations" is accepted to the Artificial Intelligence Journal! [Journal]
- Jul 20: Full-length paper for "Understanding Finite-State Representations of Recurrent Policy Networks" is now available at arXiv! [PDF]
- Jul 20: Our paper "Understanding Finite-State Representations of Recurrent Policy Networks" is accpeted to the ICML 20 XXAI workshop!
- Jun 20: My M.Sc. dissertation "Toward Disentangling the Activations of the Deep Networks via Low-dimensional Embedding and Non-negative Factorization" is now publicly available! [PDF]
- Apr 20: Demo for I-GOS is updated! It now supports user-input images, comparison against GradCam, and interactive deletion/insertion games! Go check it out! [Demo v2.0]
- Mar 20: I successfully passed my Ph.D. qualifying exam and defended my M.Sc. in Computer Science at Oregon State University! Yay! [Event]
- Feb 20: Medium post for I-GOS is now available! [Medium]
- Nov 19: Our paper "Visualizing Deep Networks by Optimizing with Integrated Gradients" is accepted to the AAAI 20. (acceptance rate 20.6%) [PDF]
- Aug 19: Code for I-GOS is now available! It is easy to use, go check it out! [Github]
- Jul 19: Early-version demo for I-GOS is no available! It does not yet support user-input images due to GPU constraints. Tune in for updtaes when more resources is available! [Demo]
- Jun 19: I-GOS is accepted to the CVPR 19 Explainable AI workshop. [PDF]
Publications
“Comparing the Decision-Making Mechanisms by Transformers and CNNs via Explanation Methods” (CVPR 24 - Oral/Best Student Paper Runners-up)
Mingqi Jiang, Saeed Khorram, Li Fuxin
[arXiv] [Project Page] [CVPR Page]

In order to gain insights about the decision-making of different visual recognition backbones, we propose two methodologies, sub-explanation counting and cross-testing, that systematically applies deep explanation algorithms on a dataset-wide basis, and compares the statistics generated from the amount and nature of the explanations. These methodologies reveal the difference among networks in terms of two properties called compositionality and disjunctivism. Transformers and ConvNeXt are found to be more compositional, in the sense that they jointly consider multiple parts of the image in building their decisions, whereas traditional CNNs and distilled transformers are less compositional and more disjunctive, which means that they use multiple diverse but smaller set of parts to achieve a confident prediction. Through further experiments, we pinpointed the choice of normalization to be especially important in the compositionality of a model, in that batch normalization leads to less compositionality while group and layer normalization lead to more. Finally, we also analyze the features shared by different backbones and plot a landscape of different models based on their feature-use similarity.
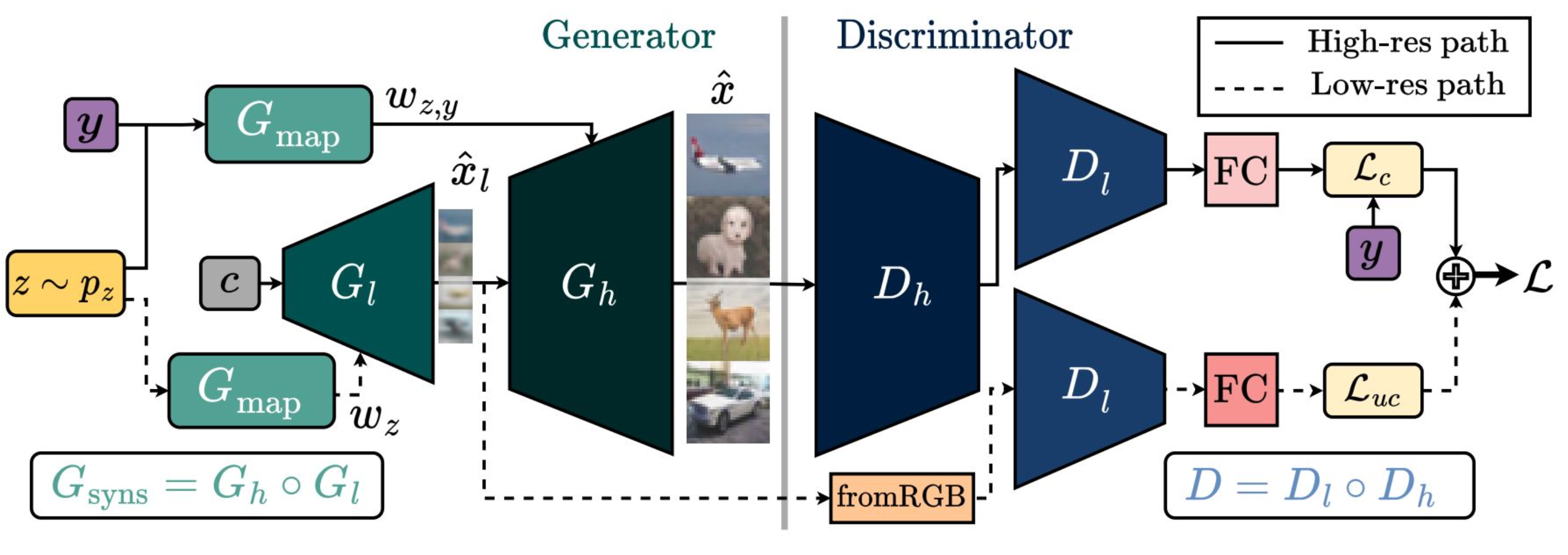
“Taming the Tail in Class-Conditional GANs: Knowledge Sharing via Unconditional Training at Lower Resolutions” (CVPR 24)
Saeed Khorram, Mingqi Jiang, Mohamad Shahbazi, Mohamad H. Danesh, Li Fuxin
[arXiv] [Code] [CVPR Page] [Poster]
CounterFactual (CF) visual explanations try to find images similar to the query image that change the decision of a vision system to a specified outcome. Existing methods either require inference-time optimization or joint training with a generative adversarial model which makes them time-consuming and difficult to use in practice. We propose a novel approach, Cycle-Consistent Counterfactuals by Latent Transformations (C3LT), which learns a latent transformation that automatically generates visual CFs by steering in the latent space of generative models. Our method uses cycle consistency between the query and CF codes in the latent space which helps our training to find better solutions. C3LT can be easily plugged into any state-of-the-art pretrained generative network. This enables our method to generate high-quality and interpretable CF examples at high-resolution images such as those in ImageNet. In addition to several established metrics for evaluating CF explanations, we introduce a novel metric tailored to assess the quality of the generated CF examples and validate the effectiveness of our method on an extensive set of experiments.
“Diverse Explanations for Object Detectors with Nesterov-Accelerated iGOS++” (BMVC 23)
Mingqi Jiang, Saeed Khorram, Li Fuxin
[PDF] [Code]
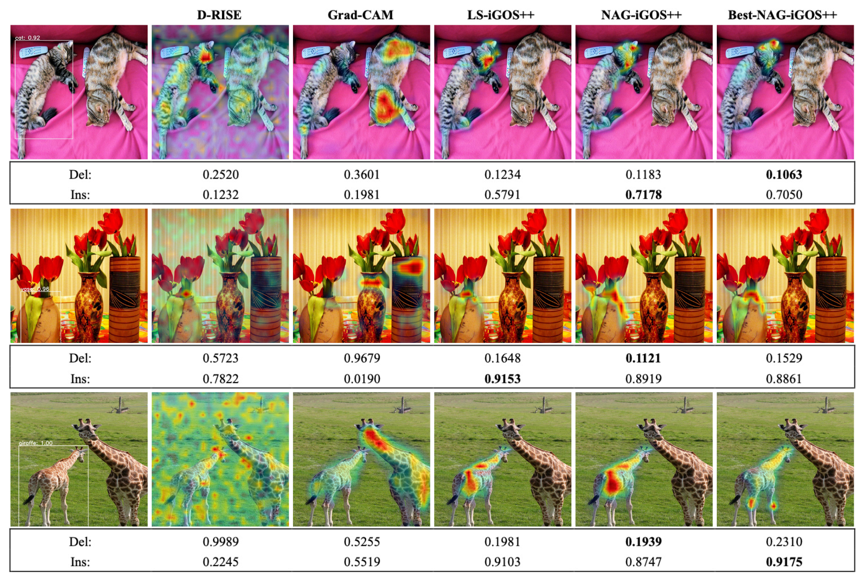
Object detection is a crucial task in computer vision, with applications ranging from autonomous driving to surveillance systems. However, few have approached the problem of explaining object detections to gain more insights. In this paper, we extend iGOS++, an explanation algorithm of image classification models, to the task of object detection. Our extension consists of two novel aspects. The first is to utilize Nesterov Accelerated Gradient (NAG) to improve the optimization with integrated gradients. This significantly improves over the line search used in the original work in terms of both speed and quality. Besides, we propose to generate diverse explanations via different initializations of the optimization algorithm, which can better showcase the robustness of the network under different occlusions. To evaluate the effectiveness of our algorithm, we conduct experiments on the MS COCO and PASCAL VOC datasets. Results demonstrate that our approach significantly outperforms existing methods in terms of both explanation quality and speed. Besides, the diverse explanations it generates give more insight into the (sometimes erroneous) mechanisms underlying deep object detectors.
“Cycle-Consistent Counterfactuals by Latent Transformations” (CVPR 22)
Saeed Khorram, Li Fuxin
[arXiv] [Code] [Poster]

CounterFactual (CF) visual explanations try to find images similar to the query image that change the decision of a vision system to a specified outcome. Existing methods either require inference-time optimization or joint training with a generative adversarial model which makes them time-consuming and difficult to use in practice. We propose a novel approach, Cycle-Consistent Counterfactuals by Latent Transformations (C3LT), which learns a latent transformation that automatically generates visual CFs by steering in the latent space of generative models. Our method uses cycle consistency between the query and CF codes in the latent space which helps our training to find better solutions. C3LT can be easily plugged into any state-of-the-art pretrained generative network. This enables our method to generate high-quality and interpretable CF examples at high-resolution images such as those in ImageNet. In addition to several established metrics for evaluating CF explanations, we introduce a novel metric tailored to assess the quality of the generated CF examples and validate the effectiveness of our method on an extensive set of experiments.
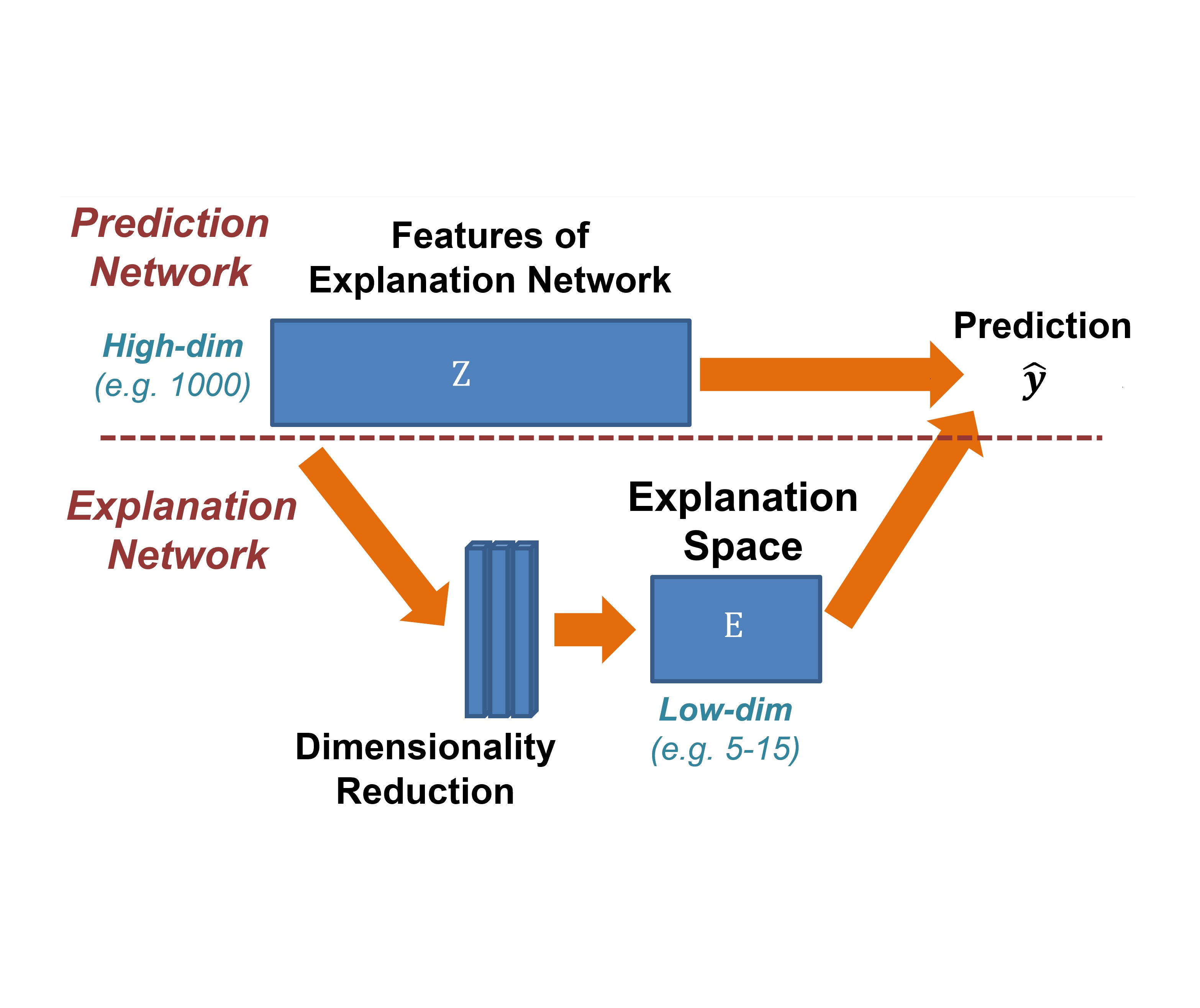
From Heatmaps to Structured Explanations of Image Classifiers (Applied AI Letters 21)
Li Fuxin, Zhongang Qi, Saeed Khorram, Vivswan Shitole, Prasad Tadepalli, Minsuk Kahng, Alan Fern
[PDF]
This paper summarizes our endeavors in the past few years in terms of explaining image classifiers, with the aim of including negative results and insights we have gained. The paper starts with describing the explainable neural network (XNN), which attempts to extract and visualize several high-level concepts purely from the deep network, without relying on human linguistic concepts. This helps users understand network classifications that are less intuitive and substantially improves user performance on a difficult fine-grained classification task of discriminating among different species of seagulls. Realizing that an important missing piece is a reliable heatmap visualization tool, we have developed I-GOS and iGOS++ utilizing integrated gradients to avoid local optima in heatmap generation, which improved the performance across all resolutions. During the development of those visualizations, we realized that for a significant number of images, the classifier has multiple different paths to reach a confident prediction. This has lead to our recent development of structured attention graphs (SAGs), an approach that utilizes beam search to locate multiple coarse heatmaps for a single image, and compactly visualizes a set of heatmaps by capturing how different combinations of image regions impact the confidence of a classifier. Through the research process, we have learned much about insights in building deep network explanations, the existence and frequency of multiple explanations, and various tricks of the trade that make explanations work. In this paper, we attempt to share those insights and opinions with the readers with the hope that some of them will be informative for future researchers on explainable deep learning.
Re-Understanding Finite-State Representations of Recurrent Policy Networks (ICML 21)
Mohamad H. Danesh, Anurag Koul, Alan Fern, Saeed Khorram
[PDF] [Code] [Presentation]
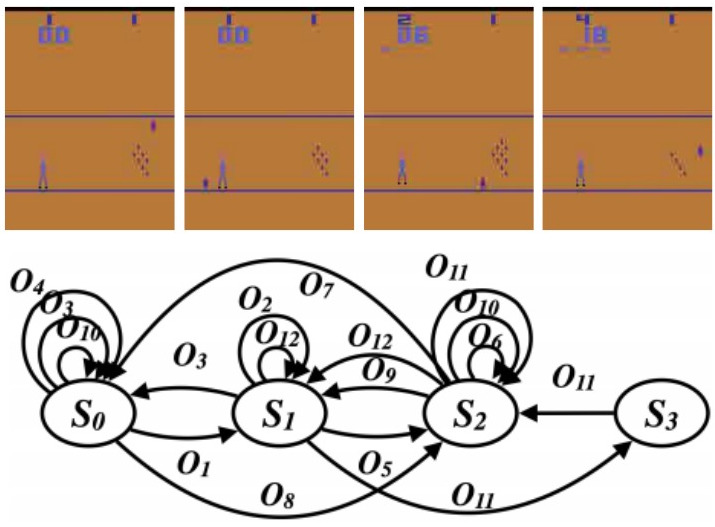
We introduce an approach for understanding control policies represented as recurrent neural networks. Recent work has approached this problem by transforming such recurrent policy networks into finite-state machines (FSM) and then analyzing the equivalent minimized FSM. While this led to interesting insights, the minimization process can obscure a deeper understanding of a machine’s operation by merging states that are semantically distinct. To address this issue, we introduce an analysis approach that starts with an unminimized FSM and applies more-interpretable reductions that preserve the key decision points of the policy. We also contribute an attention tool to attain a deeper understanding of the role of observations in the decisions. Our case studies on 7 Atari games and 3 control benchmarks demonstrate that the approach can reveal insights that have not been previously noticed.
Stochastic Block-ADMM for Training Deep Networks (pre-print)
Saeed Khorram, Xiao Fu, Mohammad H. Danesh, Zhongang Qi, Li Fuxin
[PDF]

In this paper, we propose Stochastic Block-ADMM as an approach to train deep neural networks in batch and online settings. Our method works by splitting neural networks into an arbitrary number of blocks and utilizes auxiliary variables to connect these blocks while optimizing with stochastic gradient descent. This allows training deep networks with non-differentiable constraints where conventional backpropagation is not applicable. An application of this is supervised feature disentangling, where our proposed DeepFacto inserts a non-negative matrix factorization (NMF) layer into the network. Since backpropagation only needs to be performed within each block, our approach alleviates vanishing gradients and provides potentials for parallelization. We prove the convergence of our proposed method and justify its capabilities through experiments in supervised and weakly-supervised settings.
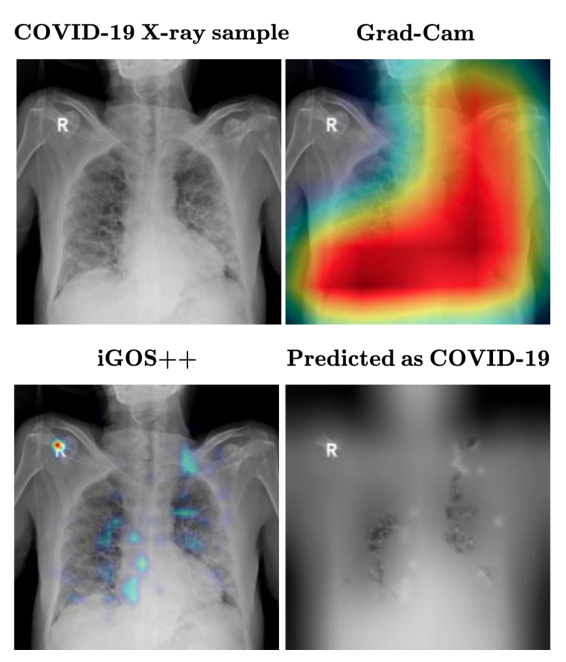
iGOS++: Integrated Gradient Optimized Saliency by Bilateral Perturbations (ACM-CHIL 21)
Saeed Khorram*, Tyler Lawson*, Li Fuxin
[PDF] [Code] [Poster] [Presentation]

The black-box nature of the deep networks makes the explanation for "why" they make certain predictions extremely challenging. Saliency maps are one of the most widely-used local explanation tools to alleviate this problem. One of the primary approaches for generating saliency maps is by optimizing a mask over the input dimensions so that the output of the network is influenced the most by the masking. However, prior work only studies such influence by removing evidence from the input. In this paper, we present iGOS++, a framework to generate saliency maps that are optimized for altering the output of the black-box system by either removing or preserving only a small fraction of the input. Additionally, we propose to add a bilateral total variation term to the optimization that improves the continuity of the saliency map especially under high resolution and with thin object parts. The evaluation results from comparing iGOS++ against state-of-the-art saliency map methods show significant improvement in locating salient regions that are directly interpretable by humans. We utilized iGOS++ in the task of classifying COVID-19 cases from x-ray images and discovered that sometimes the CNN network is overfitted to the characters printed on the x-ray images when performing classification. Fixing this issue by data cleansing significantly improved the precision and recall of the classifier.
Visualizing Deep Networks by Optimizing with Integrated Gradients (CVPRW 19/AAAI 20)
Zhongang Qi, Saeed Khorram, Li Fuxin
[PDF] [Demo] [Code] [Medium]
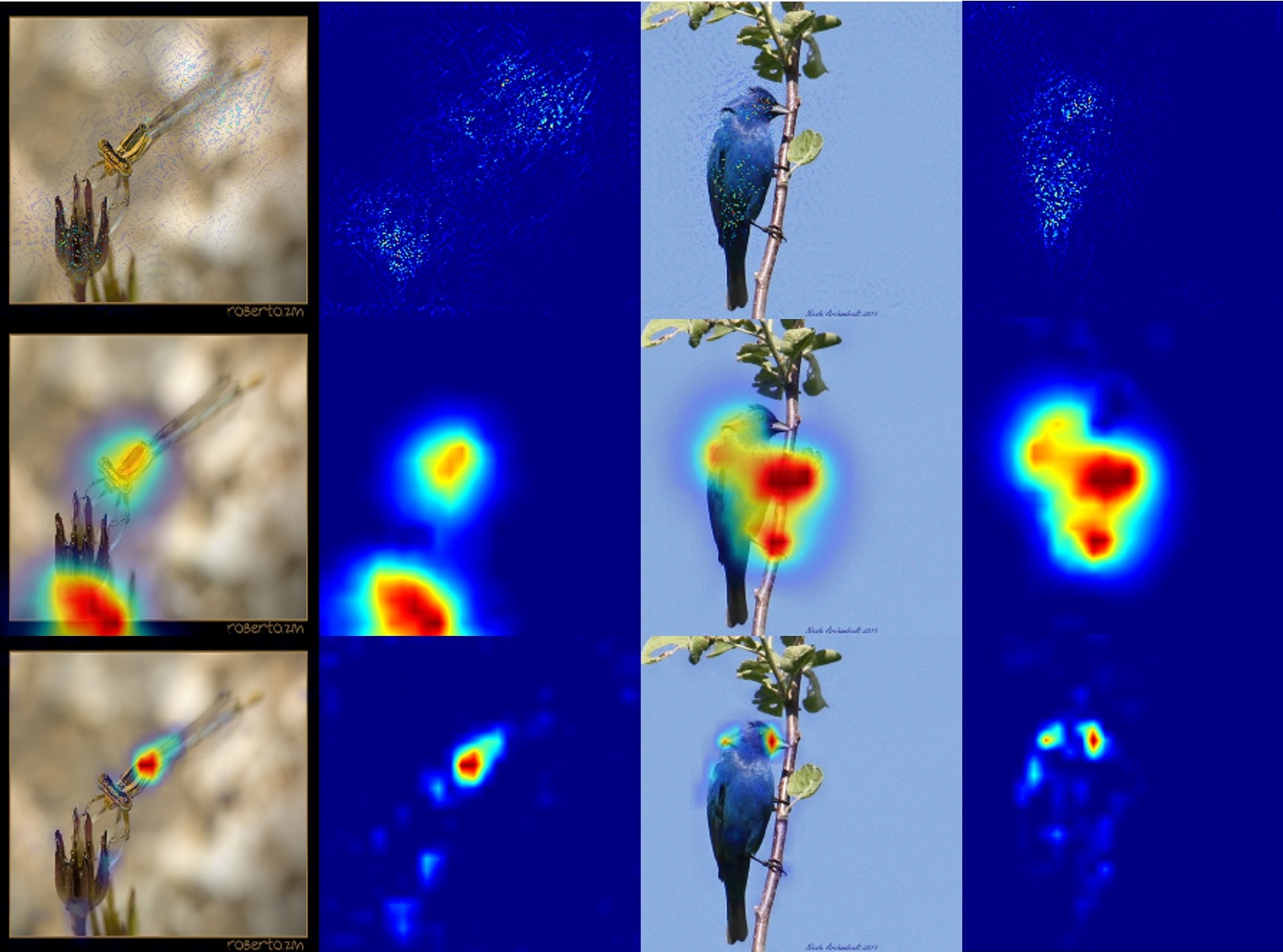
Understanding and interpreting the decisions made by deep learning models is valuable in many domains. In computer vision, computing heatmaps from a deep network is a popular approach for visualizing and understanding deep networks. However, heatmaps that do not correlate with the network may mislead human, hence the performance of heatmaps in providing a faithful explanation to the underlying deep network is crucial. In this paper, we propose I-GOS, which optimizes for a heatmap so that the classification scores on the masked image would maximally decrease. The main novelty of the approach is to compute descent directions based on the integrated gradients instead of the normal gradient, which avoids local optima and speeds up convergence. Compared with previous approaches, our method can flexibly compute heatmaps at any resolution for different user needs. Extensive experiments on several benchmark datasets show that the heatmaps produced by our approach are more correlated with the decision of the underlying deep network, in comparison with other stateof-the-art approaches.
Embedding Deep Networks into Visual Explanations (Artificial Intelligence Journal 2020)
Zhongang Qi, Saeed Khorram, Li Fuxin
[PDF] [Code]